
Предположим, имеются два
наблюдения текущей координаты ![]() положения объекта с
приемников ГЛОНАСС и GPS:
положения объекта с
приемников ГЛОНАСС и GPS:
![]() -
наблюдение с ГЛОНАСС,
-
наблюдение с ГЛОНАСС,
![]() -
наблюдение с GPS,
-
наблюдение с GPS,
где ![]() и
и ![]() -
независимые величины шума (погрешности измерений) с известными дисперсиями
-
независимые величины шума (погрешности измерений) с известными дисперсиями ![]() и
и ![]() и нулевыми математическими
ожиданиями (средними значениями). На основе этих двух наблюдений нужно
вычислить значение координаты
и нулевыми математическими
ожиданиями (средними значениями). На основе этих двух наблюдений нужно
вычислить значение координаты ![]() . Точно узнать значение
. Точно узнать значение ![]() , как правило, невозможно. Можно лишь
уточнить значения наблюдений
, как правило, невозможно. Можно лишь
уточнить значения наблюдений ![]() и
и ![]() ,
стараясь максимально приблизиться к истинному значению координаты, т.е.
избавиться от шумовых составляющих
,
стараясь максимально приблизиться к истинному значению координаты, т.е.
избавиться от шумовых составляющих ![]() и
и ![]() .
.
Если случайные величины ![]() и
и ![]() подчиняются нормальному
закону распределения, то наилучшее приближение (наилучшую оценку)
подчиняются нормальному
закону распределения, то наилучшее приближение (наилучшую оценку) ![]() можно построить по правилу
можно построить по правилу
![]() , (1)
, (1)
где ![]() и
и ![]() -
некоторые (пока еще неизвестные) весовые коэффициенты, которые влияют на
качество оценки
-
некоторые (пока еще неизвестные) весовые коэффициенты, которые влияют на
качество оценки ![]() . Можно заметить, если сумма
коэффициентов
. Можно заметить, если сумма
коэффициентов
![]() , (2)
, (2)
то, оценка, построенная по линейному алгоритму (1),
в среднем, будет равна истинному значению ![]() , т.е.
будет несмещенной:
, т.е.
будет несмещенной:
![]() ,
,
где ![]() - оператор
математического ожидания.
- оператор
математического ожидания.
Для решения нашей задачи
необходимо выполнение условия (2), иначе оценка будет «уходить» либо вниз, либо
вверх от истинного значения координаты ![]() . Учитывая
условие (2), алгоритм (1) можно переписать в виде:
. Учитывая
условие (2), алгоритм (1) можно переписать в виде:
![]()
или, заменяя ![]() ,
,
![]() (3)
(3)
Алгоритм (3) описывает принцип
построения оценок с помощью фильтра Калмана, а неизвестный коэффициент ![]() выбирается так, чтобы минимизировать
критерий качества для оценки
выбирается так, чтобы минимизировать
критерий качества для оценки ![]() .
.
Рассмотрим вид критерия качества
для решения указанной задачи, используемый в фильтре Калмана. Очевидно, что при
построении оценки ![]() будет возникать ошибка
будет возникать ошибка
![]()
и желательно, чтобы эта ошибка была как можно меньше. Чтобы оценивать качество работы алгоритма (3) выберем функцию потерь (штрафа) в виде
![]() , (4)
, (4)
которая будет возрастать при возрастании ошибки и
убывать при ее уменьшении. Преимущество такого выбора функции потерь в том, что
она имеет один глобальный минимум и в этой точке существует производная. Это
значит, что на ее основе можно аналитически построить алгоритм вычисления
оценки ![]() . Однако, что функция (4), вообще говоря,
является случайной величиной, т.к. от измерения к измерению меняются
погрешности
. Однако, что функция (4), вообще говоря,
является случайной величиной, т.к. от измерения к измерению меняются
погрешности ![]() и
и ![]() , что приводит и к
изменению значения оценки
, что приводит и к
изменению значения оценки ![]() , при одном и том же
алгоритме обработки наблюдений. Поэтому критерий качества следует выбрать таким
образом, чтобы алгоритм давал в среднем минимум функции
, при одном и том же
алгоритме обработки наблюдений. Поэтому критерий качества следует выбрать таким
образом, чтобы алгоритм давал в среднем минимум функции ![]() ,
т.е.
,
т.е.
![]() . (5)
. (5)
Выражение (5) можно интерпретировать как минимум
дисперсии ошибки оценивания, т.к. случайная величина ![]() имеет
нулевое математическое ожидание, то ее возведение в квадрат
имеет
нулевое математическое ожидание, то ее возведение в квадрат ![]() дает дисперсию ошибки оценивания:
дает дисперсию ошибки оценивания:
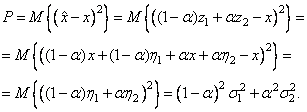 (6)
(6)
Последнее выражение показывает,
что дисперсия ![]() зависит от коэффициента
зависит от коэффициента ![]() , оптимальное значение которого находится в
точке минимума дисперсии
, оптимальное значение которого находится в
точке минимума дисперсии ![]() . Учитывая, что в точке
минимума производная равна нулю, получаем уравнение для вычисления коэффициента
. Учитывая, что в точке
минимума производная равна нулю, получаем уравнение для вычисления коэффициента
![]() :
:
![]() .
.
и после вычисления производной, получаем
![]() ,
,
откуда имеем
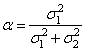 . (7)
. (7)
Выражение (7) определяет оптимальное значение
коэффициента ![]() для построения оценки
для построения оценки ![]() и алгоритм (3) принимает вид
и алгоритм (3) принимает вид
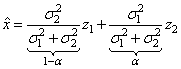 (8)
(8)
Уравнение (8) является примером
реализации фильтра Калмана для задачи построения оценки координаты ![]() по двум наблюдениям
по двум наблюдениям ![]() и
и
![]() с независимым гауссовсовским шумом
(погрешностями наблюдений). Из выражения (8) видно, что если
с независимым гауссовсовским шумом
(погрешностями наблюдений). Из выражения (8) видно, что если ![]() (GPS дает более точные значения, чем ГЛОНАСС), то больше
информации будет извлекаться из наблюдения
(GPS дает более точные значения, чем ГЛОНАСС), то больше
информации будет извлекаться из наблюдения ![]() и меньше
из
и меньше
из ![]() . Если же
. Если же ![]() , то
выражение (8) приобретает вид
, то
выражение (8) приобретает вид ![]() , т.е. происходит
усреднение наблюдений. При этом, в каждом конкретном случае можно вычислить
значение дисперсии ошибки оценивания
, т.е. происходит
усреднение наблюдений. При этом, в каждом конкретном случае можно вычислить
значение дисперсии ошибки оценивания ![]() , т.е. узнать насколько
улучшилась оценка
, т.е. узнать насколько
улучшилась оценка ![]() по сравнению с исходными
наблюдениями
по сравнению с исходными
наблюдениями ![]() и
и ![]() . Для этого достаточно
подставить оптимальное значение коэффициента
. Для этого достаточно
подставить оптимальное значение коэффициента ![]() в
выражение (6) и сделать несложные математические преобразования:
в
выражение (6) и сделать несложные математические преобразования:
 (9)
(9)
следовательно,
![]() (10)
(10)
т.е. оптимальное значение коэффициента ![]() также равно дисперсии ошибки оценивания
деленной на дисперсию
также равно дисперсии ошибки оценивания
деленной на дисперсию ![]() погрешности второго наблюдения.
погрешности второго наблюдения.
Обычно фильтр Калмана записывают в виде
![]() ,
,
и, подставляя вместо ![]() значение
(10), получаем известную запись алгоритма калмановской фильтрации:
значение
(10), получаем известную запись алгоритма калмановской фильтрации:
![]()
где ясно видно, что наблюдение ![]() уточняется наблюдением
уточняется наблюдением ![]() корректирующим коэффициентом
корректирующим коэффициентом ![]() .
.
Теперь предположим, что в рамках решаемой задачи, появилось еще одно наблюдение
![]() ,
,
координаты ![]() от
независимого источника информации. Тогда для уточнения текущей оценки
от
независимого источника информации. Тогда для уточнения текущей оценки ![]() представим ее как первое наблюдение
представим ее как первое наблюдение
![]() ,
,
с известной величиной дисперсии погрешности ![]() . В результате получим следующий алгоритм
обработки наблюдений:
. В результате получим следующий алгоритм
обработки наблюдений:
![]() (11)
(11)
где ![]() в соответствии с
выражением (9) вычисляется как
в соответствии с
выражением (9) вычисляется как
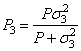 . (12)
. (12)
Формулы (11) и (12) показывают принцип
рекуррентного вычисления оценок (уточнения оценки) в фильтре Калмана по серии
наблюдений ![]() Рекуррентное вычисление оценок является
главным преимуществом фильтра Калмана перед другими способами фильтрации,
используя на каждом шаге только два наблюдения. Вместе с тем, модель, в которой
текущее наблюдение корректируется лишь предыдущим, соответствует марковской модели,
где текущее состояние дает полную информацию для статистического описания
поведения процесса в «будущем». Простым примером марковской модели может
служить изменение координаты движения объекта в пространстве, когда знание его
текущей координаты достаточно для вероятностного описания движения объекта в
«будущем». При этом «знать» где он был «в прошлом» нет необходимости. Только
для таких моделей фильтр Калмана дает оптимальные оценки. В ином случае
необходимо либо соглашаться с неоптимальностью работы алгоритма, либо применять
другие методы фильтрации.
Рекуррентное вычисление оценок является
главным преимуществом фильтра Калмана перед другими способами фильтрации,
используя на каждом шаге только два наблюдения. Вместе с тем, модель, в которой
текущее наблюдение корректируется лишь предыдущим, соответствует марковской модели,
где текущее состояние дает полную информацию для статистического описания
поведения процесса в «будущем». Простым примером марковской модели может
служить изменение координаты движения объекта в пространстве, когда знание его
текущей координаты достаточно для вероятностного описания движения объекта в
«будущем». При этом «знать» где он был «в прошлом» нет необходимости. Только
для таких моделей фильтр Калмана дает оптимальные оценки. В ином случае
необходимо либо соглашаться с неоптимальностью работы алгоритма, либо применять
другие методы фильтрации.